“2 1+ 1 sections”: a quick way to refer to a part of a picture
Posted by Jim DeLaHunt on 31 Oct 2018 at 11:22 pm | Tagged as: robobait, software engineering
For one of my consulting clients, I found myself writing command-line tools that operate on videos. One tool zoomed in on the portion of the video frame, to let the user examine it closely. How do you tell a command-line tool to zoom in on one portion of video frame? I came up with an idea, which I call “2 1+ 1 sections”. It is a quick way for a user to refer to a part of a picture, using a concise text notation. I haven’t used it for that client, but I’ll post it here in case it comes in useful later on.
Imagine you have picture, like this view of Pismo Beach (California):

Now, suppose you want to zoom in on the white house in the upper-right corner. If you have a GUI app, you can click on the area of interest with the pointer. If you have a touch-screen interface, you can pinch-zoom with your fingers. But in a command-line situation, these aren’t practical.
My idea? A scheme I call “2 1+ 1 sections”. I intend this scheme to provide a quick way for a human operator to refer to part of a picture, using a concise text tag. This is especially helpful for someone typing a command to a program, who needs to pass an argument which refers to part of the image, and is in a hurry. Imagine the operator thinking, “the house is in the top right, that’s section 212”, and typing “212” as an argument to that command-line program.
So how does it work? The first insight of the “2 1+ 1 sections” idea is to divide the the picture into n equal parts, horizontally and vertically. For instance, let’s divide this image into 2 x 2 equal parts, giving four parts in all.

This division makes it easy to refer to something contained clearly within one of the quadrants (let’s call them “sections”). We can see that the house is in the top-right section.
We need a way of referring to sections. I give each section a 3-part name. The parts are: “n, row, column”. The first part is n, a digit giving the number by which the width and height are divided. In this case, the original image is divided into 2 sections horizontally and 2 sections vertically, so the first part is “2”. The second part is the row index: 1 for the first row, 2 for the second. The third part is the column index: 1 for the left column, 2 for the right column.
So, the house is in the top-right section, section “212”. “212” is a compact way of saying, “divide the image into 2 parts horizontally and vertically, select the section which is in row 1 and column 2”.
The problem with dividing an image into four sections is that there are four boundaries between sections. Suppose we want to refer to a part of the image which at one of those boundaries. For instance, consider the line of surf to the left, and the pools and rocks just inshore of them. We can take the top row of sections, shift them down by half a section-height, so they straddle the line dividing row 1 from row 2. We don’t do this to the bottom-most row of sections, because that would move them out of the bounds of the image.Here is the row of sections, shifted down by half a section-height, shown in yellow:

This row of sections is shifted down from row 1, so the row part of its section number is “1+”. The plus sign indicates the half-distance shift. Many symbols could work for this purpose. I considered “.”, “/”, and the fraction “one-half”, before settling on “+”. But when I upload these illustrations to a website, the “+” symbol in their section numbers was dropped, so I had to change the “+” to a letter “p” for that usage. The choice of symbol isn’t the point, the shifting of the sections is the point.
The line of surf to the left of the image, and the pools and rocks just inshore of them, can be referred to as “section 21+1” of this image. The scrap of beach at the right of the image is clearly in “section 21+2”.
Similarly, we can shift column 1 of sections to the right by half a section-width, shown in red:

The ridge in the background at the top of the image is clearly in “section 211+”.
Finally, you can shift sections to both the right and down by a half-section. In a division by 2, there is only one such section. Shifting column 2 right, or row 2 down, moves the sections off the edge of the image. Here is one section, shifted right and down, shown in orange:

The linear rocks, partially submerged, in the centre of the image are in “section 21+1+”.
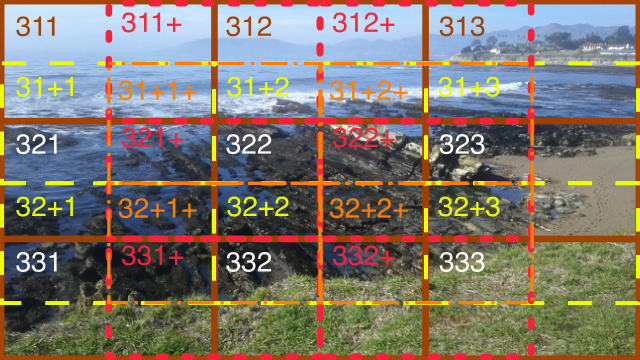
This system works equally well for division into more rows and columns, that is, for larger values of n. Here is the division of the same image into thirds (n = 3).

The first part of each section name is “3”, because width and height are divided into 3 parts (n = 3). There are now 3 rows and 3 columns.
The white house in the upper right of the image is in “section 313”.
For the “3xx” section, there are six more sections with rows shifted down a half-section, and six more sections with columns shifted right a half-section, and four sections with both rows and columns shifted right. Here is that final group of four:

And here are all the sections in the division by 3. There are 9 + 6 + 6 + 4 = 25 sections in all.
This scheme can be extended to higher and higher values of n. There will be (2n – 1) ** 2 sections for any value of n. All sections have the same dimensions, and have positions distributed uniformly across the original image. The only practical limit on n is the user’s ability to divide the image up mentally, and come up with the three-part section code quickly and easily. I suspect that division by 2 or 3 will prove easy; division by 4 or 5 will require training and practice, or a kind of image content that aids in the spatial estimation; and that division by higher numbers will prove impractical.
There is value to using the highest value of n which is comfortable. A reference to “section 313” bounds more closely the area of interest more closely than “section 212” does.I can imagine using this scheme interatively with a command-line tool. For instance, I could run the tool to take a large image and give me “section 32+1” of the image, and produce an image with just that section. If I need to zoom in further, I could perhaps run that tool again, this time providing two section numbers. The tool uses each section number in sequence to zoom in more than one time.
My name for this scheme is “2 1+ 1 sections”. It gives a thumbnail sketch of the section numbering scheme, including the notation for the sections offset by a half-width and/or half-height, in the scheme’s title. I suspect people might shorten it to “211 sections”. A mathematician might prefer to call it “n x y sections” though.
In a bit of web searching, I couldn’t find this same idea published by someone else. Just possibly, I’m the first person with this idea. More likely, I’ve independently recreated a good idea someone else already had, under a different name. If you know of this elsewhere, please leave me a comment telling me about it.